




Sztuczna inteligencja, w tym algorytmy oparte o głębokie sieci neuronowe stają się w ostatnim czasie coraz bardziej popularne. Generatory obrazu czy złożone modele do przetwarzania tekstu takie jak GPT cieszą się obecnie ogromnym zainteresowaniem. W związku z tym wiele osób myśli o tym, żeby zdobyć umiejętności potrzebne do trenowania podobnych modeli. Zanim jednak zabierzemy się za trenowanie tak zaawansowanych algorytmów, warto poznać podstawy, czyli klasyczne modele uczenia maszynowego. Dzielą się one z grubsza na trzy kategorie- regresję, klasyfikację oraz klasteryzację. Regresja to sposób na przewidywanie wartości zmiennych numerycznych- takich jak cena czy wysokość zarobków- na podstawie danych wejściowych, również w postaci liczbowej. Klasyfikacja także operuje na danych numerycznych, ale wyjściem takiego algorytmu jest informacja w postaci kategorii, często binarnej - 0/1, prawda/fałsz, tak/nie. Klasteryzacja za to polega na wykrywaniu w danych tak zwanych klastrów, czyli grupowaniu obserwacji w oparciu o prawidłowości, które nie zostały wcześniej stwierdzone i oznakowane. Ze wszystkich tych trzech grup prawdopodobnie największa różnorodność dostępnych algorytmów występuje w pozornie najprostszej z nich- klasyfikacji.
Czym jest klasyfikacja w kontekście uczenia maszynowego?
Klasyfikacja to proces przypisania jakiejś obserwacji do jednej ze z góry przyjętych kategorii. Przykładem może być ubieganie się o kredyt w banku. Nasz wniosek da się uprościć do zestawu liczb takich jak: wiek, stan cywilny (zmienna kategoryczna, którą można reprezentować w postaci liczby), płeć, wysokość zarobków itd. Następnie jakiś algorytm na podstawie tych liczb będzie miał za zadanie wydać decyzję- przyznanie kredytu (1) albo jego odmowa (0). W niektórych problemach kategorii może być więcej niż dwie, ale klasyfikacja binarna jest spotykana najczęściej, więc takie właśnie problemy będziemy rozpatrywać. W jaki sposób można wydać taką decyzję? Z pewnością istnieją różne sposoby, a jednym z nich jest skorzystanie z wiedzy eksperta. Doświadczony pracownik banku potrafi ocenić ryzyko braku spłaty zadłużenia w konkretnym przypadku i na tej podstawie odmówić udzielenia kredytu. Jednak pomimo dużej wiedzy wymaganej do wykonywania takiego zawodu, proces decyzyjny można w tym przypadku łatwo zautomatyzować (a co za tym idzie- zaoszczędzić). W jaki sposób? Wystarczy przeanalizować dane uczące, czyli pewną liczbę historycznych wniosków (tysiące, może nawet dziesiątki albo setki tysięcy) i wychwycić zależności, jakie istnieją między danymi wejściowymi- cechami osoby wnioskującej- a decyzją. Jest to problem na tyle złożony, że ciężko ułożyć właściwy algorytm człowiekowi, który przeanalizuje dane ręcznie i wyciągnie z nich wnioski. Istnieją jednak sposoby na to, aby proces decyzyjny zautomatyzować i na tym właśnie polega zagadnienie klasyfikacji w uczeniu maszynowym.
Przykłady algorytmów klasyfikujących
Istnieją różne modele do klasyfikacji i każdy charakteryzuje się innymi cechami. W zależności od problemu, nad jakim pracujemy, będziemy mogli dobrać inny algorytm. Kilka przykładowych znajduje się w poniższym zestawieniu.
Regresja logistyczna
Ten algorytm uchodzi za jeden z najprostszych i często nie jest wystarczający w złożonych zagadnieniach. Dobrze się sprawdza jednak w problemach liniowych, czyli takich gdzie zawsze wraz ze wzrostem jakiejś danej wejściowej rośnie prawdopodobieństwo, że wynikiem klasyfikacja jest klasa 1 (albo 0). Przykładowo jeśli dla grupy dorosłych ludzi chcemy określić ich płeć na podstawie wzrostu oraz wagi to zwiększając wartości obu tych parametrów prawdopodobieństwo, że dana osoba jest mężczyzną, zawsze rośnie. Wynika to z tego, że mężczyźni są statystycznie wyżsi i ciężsi. Gdyby jednak powyżej przekroczenia pewnej granicy wzrostu (np. 180 cm) zaczęło rosnąć prawdopodobieństwo, że dana osoba jest kobietą, to model liniowy okazałby się nieskuteczny.
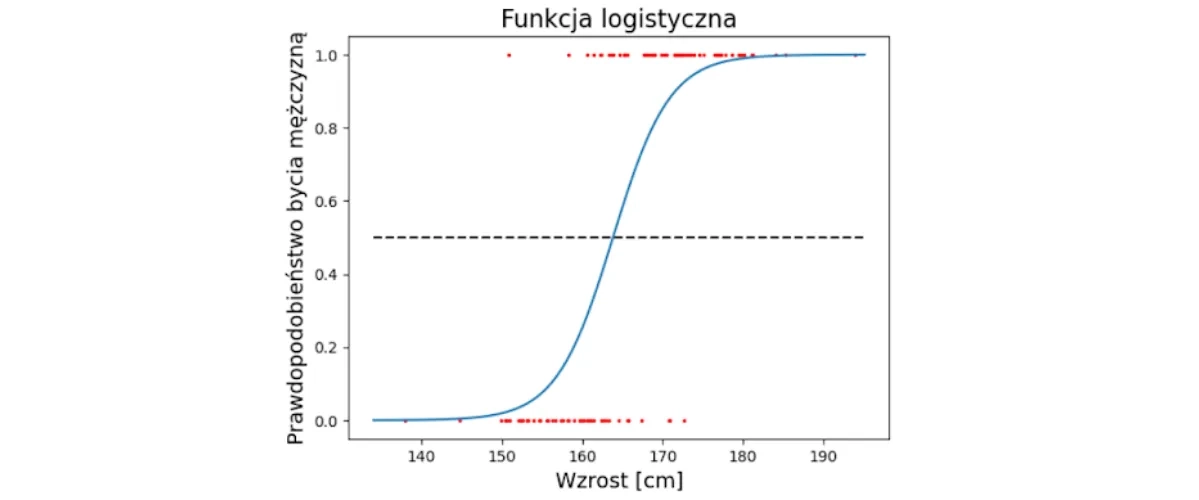
Oto w jaki sposób działa regresja logistyczna. Poniższy przykład obrazuje to dla tylko jednej zmiennej wejściowej „wzrost”, ale model można uogólnić.
- Zaczynamy od tego, żeby prognozowaną kategorię zapisać w postaci zero-jedynkowej. Ostatecznie wszystkie przetwarzane dane muszą zostać zamienione na liczby.
- Następnie dla lepszego zrozumienia przedstawmy wszystkie dane uczące na wykresie. Są to czerwone punkty, których położenie (x, y) wynika z kombinacji parametrów (wzrost, płeć). Chociaż nie istnieje wyraźna granica między wzrostem obydwu płci, to widzimy, że u kobiet współrzędne wzdłuż osi x są przesunięte bardziej w lewo a u mężczyzn- w prawo.
- Kolejny kluczowy krok to dopasowanie tzw. funkcji logistycznej do danych uczących. Funkcja ta określa rozkład prawdopodobieństwa przynależności do klasy 1 w zależności od wartości cechy (czyli tzw. zmiennej niezależnej) i ma postać:
gdzie: x- wartość zmiennej niezależnej, w tym przykładzie wzrost w [cm] a, b- stałe współczynniki, których wartość określa kształt wykresu funkcji logistycznej
![Sages-Blog-Banery-1199x250-KZ.webp]()



Cechy modelu regresja logistyczna:
- Model sprawdza się nieźle w problemach liniowych
- Nie wymaga dużych ilości danych
- Nie jest w stanie uchwycić złożonych zależności
- Jest podatny na zaburzenia spowodowane wartościami odstającymi w danych wejściowych
Drzewo decyzyjne
Drzewo decyzyjne jest algorytmem, którego podstawową zaletą jest wysoka interpretowalność wyników. Oznacza to, że kiedy wytrenowany model przypisze nową obserwację do którejś z klas, jesteśmy w stanie wytłumaczyć, dlaczego właśnie taka decyzja została podjęta. Jest to jeden z powodów, dla których taki algorytm dobrze sprawdzi się w przypadku wcześniej przedstawionego zagadnienia dotyczącego decyzji o przyznaniu lub odmowie udzielenia kredytu. Taka decyzja często wymaga uzasadnienia a drzewo decyzyjne nam je zapewnia. Model ten opiera się o szereg pojedynczych pytań, na które możemy odpowiedzieć „tak” lub „nie”. Odpowiadając na nie w odpowiedniej kolejności, dochodzimy w końcu do finalnej decyzji, do której klasy przypisać obserwację.
Poniższe drzewo obrazuje schemat podejmowania decyzji o przyznaniu kredytu dla wnioskujących, którzy są scharakteryzowani przez takie cechy jak:
- Credit history (czy aplikant ma historię kredytową- tak/nie)
- Applicant income (dochód aplikanta- zmienna numeryczna)
- Coapplicant income (dochód koaplikanta- zmienna numeryczna)
- Loan amount (pożyczona kwota- zmienna numeryczna)
- Loan amount term (czas trwania kredytu w miesiącach- zmienna numeryczna)
W pierwszym kroku sprawdzamy, czy historia kredytowa wynosi 0 (innymi słowy czy jest <=0.5). Jeśli tak (strzałka w lewo) to przechodzimy do kolejnego pytania dotyczącego dochodu koaplikanta. Jeśli nie (strzałka w prawo) to pytamy o czas trwania kredytu. Odpowiadając na kolejne pytania, dochodzimy finalnie do węzła, w którym nie ma dalszych pytań a informacja o klasie na tym węźle (class=0 albo class=1) jest wynikiem klasyfikacji.
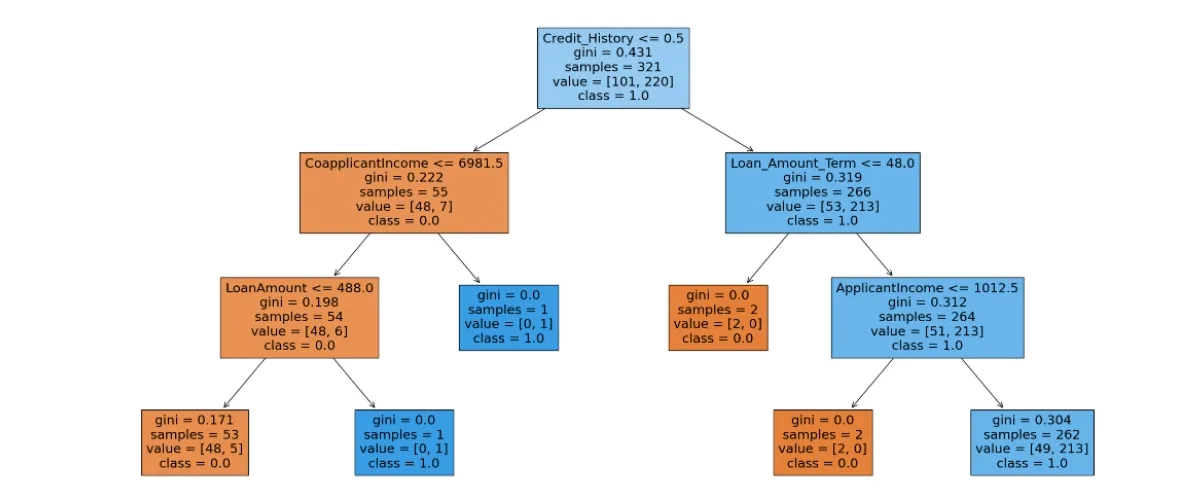
Może pojawić się pytanie- skąd wiemy, jak dobrać kolejne pytania i wartości graniczne w nich zawarte? Na tym właśnie polega trenowanie modelu. Na podstawie danych uczących pytania dobrane są tak, żeby w jak najmniejszej ich liczbie jak najlepiej sklasyfikować analizowane obserwacje. Co za tym idzie- będziemy stopniowo dzielić zbiór obserwacji na takie grupy, które w maksymalnym możliwym stopniu będą jednorodne pod względem występowania obserwacji z poszczególnych klas.
Cechy modelu drzewo decyzyjne:
- Drzewa decyzyjne są wysoce interpretowalne
- Ich dokładność jest całkiem dobra nawet dla problemów nieliniowych
- Drzewa możemy łączyć w większe zespoły (ang. enseble)
- Model ten jest odporny na wartości odstające
K Nearest Neighbours
Ostatnim modelem, jaki zostanie tutaj opisany jest K Nearest Neighbours. Ten algorytm jest bardzo prosty i sprawdza się najlepiej dla cech (zmiennych wejściowych), których wymiar jest taki sam, to znaczy na przykład, że wszystkie określają jakiś rozmiar w konkretnej jednostce miary. Najłatwiej zrozumieć jego działanie dla danych, w których występują dwie cechy- będą one odpowiadać dwóm wymiarom przestrzennym. Na taką dwuwymiarową przestrzeń należy nanieść dane uczące w postaci punktów. Oprócz położenia (x, y) każdy z tych punktów będzie posiadał informację o klasie, do jakiej należy. Następnie dla każdej nowej obserwacji sprawdzamy, do jakiej klasy należy K (dowolna całkowita liczba dodatnia) najbliższych sąsiadów tego punktu w danej przestrzeni. Wartość K możemy przyjąć według uznania, ale zwykle jest ona mniejsza niż 10.
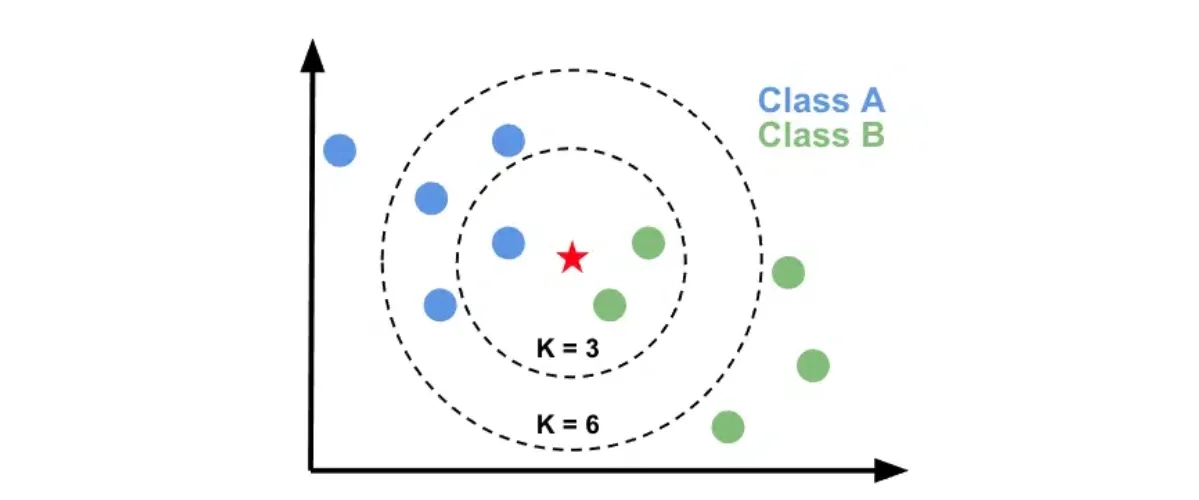
Przykładowo na powyższym wykresie zielone i niebieskie punkty to dane uczące należące do dwóch klas- A oraz B. Następnie nanosimy na wykres nową obserwację- gwiazdkę- i sprawdzamy, do jakiej klasy należy większość spośród K najbliższych sąsiadów nowego punktu. W tym przypadku w zależności od przyjętej wartości K wynik klasyfikacji będzie różny.
Cechy modelu K Nearest Neighbours:
- Model KNN jest prosty w zrozumieniu oraz implementacji
- Sprawdza się tylko tam, gdzie rozkład wartości dla każdej cechy jest podobny. W przeciwnym wypadku należy przeskalować dane
- Im mniej punktów wybierzemy, tym bardziej przetrenowany będzie model (overfitting)
Podsumowanie
Opisane tutaj modele to tylko wybrane przykłady algorytmów klasyfikacyjnych. Jest ich znacznie więcej i każdy ma swoje cechy charakterystyczne, wady oraz zalety. Inne klasyfikatory, których poznanie warto rozważyć to:
- Support Vector Machines
- Naive Bayes Classifier
- Random Forest Classifier
- Gradient Boosting Classifier
W nauce może pomóc serwis kaggle.com gdzie możemy znaleźć nie tylko dane, na których wytrenujemy nasze modele, ale również konkursy, w których zmierzymy się z innymi data scientistami i sprawdzimy, jak nasze klasyfikatory sprawdzą się w porównaniu z ich algorytmami. Pomocny może być również warsztat Algorytmy klasyfikacyjne w Pythonie odbywający się regularnie na Stacji IT, który wprowadza w temat klasyfikacji od zupełnych podstaw.
Jeśli zainteresował Cię artykuł, zachęcamy do sprawdzenia szkoleń z kategorii Python. Sprawdź całą ścieżkę szkoleniową Programista Python: Python podstawy, Python średnio zaawansowany i Python zaawansowany. Polecamy również szkolenia z uczenia maszynowego: Uczenie maszynowe z TensorFlow, Uczenie maszynowe w języku Python - wprowadzenie, Uczenie maszynowe w języku Python - warsztat profesjonalisty.



