



Przedstawię kilka algorytmów uczenia maszynowego, które obecnie są często stosowane do budowy modeli. Ponieważ grupą docelową są menedżerowie, moim celem nie jest precyzyjny opis, jak algorytm działa. Zamiast tego podam pewne intuicje, które pozwolą zrozumieć, dlaczego niektóre algorytmy mogą być lepsze od innych, czemu warto próbować różnych i dlaczego w konkretnym problemie możemy nie mieć możliwości wykorzystania któregoś z nich.
Regresja liniowa i logistyczna
Jednym z najstarszych podejść do budowy modelu jest regresja liniowa. Była używana przez statystyków na długo zanim pojawiło się pojęcie "uczenie maszynowe". Załóżmy, że naszym celem jest zrozumienie, w jaki sposób wzrost człowieka zależy od wzrostu jego matki, ojca i płci. Być może tę relację dałoby się opisać poniższym wzorem:
wzrost = 40 + 0,3 * wzrost_matki + 0,4 * wzrost_ojca + 15 * płeć
Jak taki wzór moglibyśmy wykorzystać? Przyjmijmy, że w pewnej rodzinie urodził się syn, jego matka ma 170 cm wzrostu, ojciec 180 cm. Podstawmy te wartości do wzoru, zakładając, że syna oznaczamy przez 1, córkę przez 0. Otrzymamy poniższy wynik:
wzrost = 40 + 0,3 * 170 + 0,4 * 180 + 15 * 1 = 178
Taki wzór jest pewnym modelem (niekoniecznie słusznym), dzięki któremu jesteśmy w stanie dokonać prognozy przyszłych wartości. Ale nie tylko: możemy zrozumieć, w jaki sposób poszczególne zmienne (predyktory) są związane ze wzrostem. Jeśli matka byłaby 1 cm wyższa, dziecko powinno mieć średnio 0,3 cm więcej, z kolei jeśli urodziłaby się córka, byłaby 15 cm niższa (bo za płeć podstawilibyśmy 0). Czyli model może być wykorzystany również do wnioskowania.
Regresja liniowa to algorytm, który znajduje współczynniki (parametry, wagi) podane w powyższym wzorze (40; 0,3; 0,4; 15). Jego istotą jest założenie, że rozważana relacja ma liniową postać, to znaczy wystarczy pomnożyć wartości predyktorów przez odpowiednie liczby i je dodać. Rzeczywistość może być daleka od tego założenia.
Regresji liniowej użyjemy tylko w problemach regresyjnych, to znaczy, gdy przewidujemy zmienną ilościową. Z kolei na regresję logistyczną najprościej spojrzeć jak na modyfikację regresji liniowej, dzięki której rozwiążemy problem klasyfikacyjny. Ważne jest to, że i w tym podejściu opieramy się na założeniu o liniowości.
Kiedy warto użyć regresji? Jeśli naszym głównym celem jest zrozumienie relacji między (Y) a (X) (wnioskowanie), wtedy przyda nam się model, w którym postać tej relacji będzie dobrze widoczna --- a taką cechę ma właśnie regresja. Trzeba jednak pamiętać, że rozważana relacja wcale nie musi być liniowa. Modyfikując jednak w odpowiedni sposób predyktory, jesteśmy w stanie zamodelować również nieliniowe zależności.
Drzewo decyzyjne
Relację między wzrostem a pozostałymi zmiennymi możemy opisać przy pomocy zdań warunkowych, na przykład:
- Jeśli urodzi się dziewczynka, której matka ma powyżej 170 cm, będzie miała 168 cm.
- Jeśli urodzi się dziewczynka, której matka ma poniżej 170 cm, będzie miała 164 cm.
- Jeśli urodzi się chłopiec, którego ojciec ma powyżej 182 cm, będzie miał 180 cm.
- Jeśli urodzi się chłopiec, którego ojciec ma poniżej 182 cm, będzie miał 176 cm.
Takie zdania można przedstawić w postaci drzewa, jak poniżej.

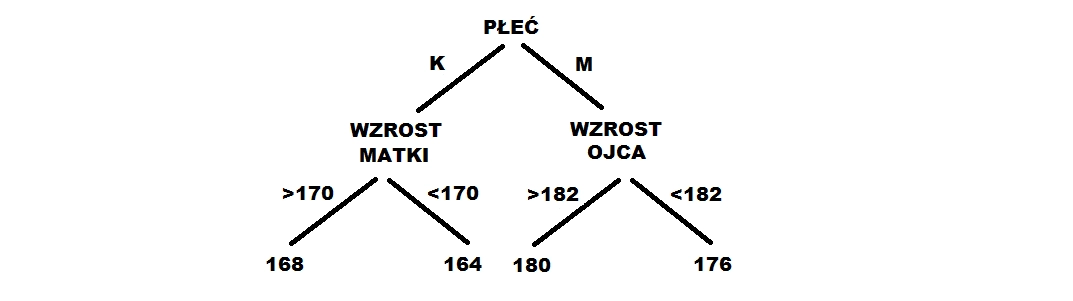
Drzewo decyzyjne to algorytm, który znajduje takie zdania warunkowe, a precyzyjniej: najlepsze punkty podziału (> 170 cm, < 170 cm), odpowiednią kolejność zmiennych (płeć jako pierwsza) oraz odpowiednie wartości (168, 164), przy pomocy których możemy przewidzieć czyjś wzrost.
Kiedy moglibyśmy chcieć użyć takiego podejścia? Drzewa nie zakładają praktycznie nic o naturze zależności między zmiennymi, są elastyczne. W prosty sposób są w stanie zamodelować tak zwane interakcje, gdy na zależność między zmiennymi wpływ mają inne zmienne (na przykład zależność ze wzrostem ojca może być inna u kobiet i mężczyzn). W przypadku regresji również można osiągnąć ten efekt, ale trzeba go wprost wprowadzić do modelu (musimy z góry założyć, że interakcja wystąpi). Dodatkowo, gdy drzewo nie jest zbyt długie, może być łatwo użyte do wnioskowania.
Las losowy, Extreme Gradient Boosting
Mimo że drzewa są elastyczne i potrafią opisać skomplikowane zależności, w praktyce często są nieprecyzyjne. Zauważmy na przykład, że w poprzednim przykładzie do prognozy używamy jedynie czterech różnych wartości: 164, 168, 176, 180. Oczywiście drzewo może być dłuższe i wtedy tych wartości będzie więcej. Mimo to, takie pojedyncze drzewo zwykle nie jest najlepszy modelem. Okazuje się, że bardzo dobrym rozwiązaniem jest budowa wielu drzew na trochę zmodyfikowanych danych (w dużym skrócie). Każde z nich wyznacza prognozę, a następnie są one w pewien sposób łączone w jedną (na przykład poprzez uśrednianie). Co ważne, taki ostateczny model przestaje być drzewem i nie ma możliwości, by w prosty sposób móc go zinterpretować.
Podejść do tego, w jaki sposób połączyć wiele drzew jest wiele. Obecnie jednymi z najpopularniejszych są lasy losowe (Random Forest) i Extreme Gradient Boosting. Różnice między nimi są trudne do prostego wytłumaczenia, ale z punktu widzenia menedżera nie mają dużego znaczenia. Ważne, że oba algorytmy są w stanie wykryć bardzo skomplikowane zależności i w praktyce często okazują się być najbardziej dokładne. Trzeba jednak pamiętać, że stanowią swego rodzaju czarne skrzynki i nie do końca wiadomo, dlaczego dokonują takich a nie innych prognoz. Są też zwykle bardzo rozbudowane i ich implementacja w końcowym produkcie może sprawić pewne problemy.
Sieć neuronowa
Sieci neuronowe mają obecnie bardzo dobry marketing. Co prawda w wielu zagadnieniach związanych ze sztuczną inteligencją rzeczywiście przy ich pomocy można uzyskać bardzo dobre wyniki, to jednak jeśli celem biznesowym nie jest rozpoznanie zmian chorobowych na zdjęciu rentgenowskim albo konstrukcja samoprowadzącego się samochodu, najprawdopodobniej sieć nie będzie najlepszym wyborem.
Na sieć neuronową najprościej spojrzeć jak na uogólnienie regresji. Główna różnica polega na tym, że algorytm ten w pewnym sensie jest w stanie sam znaleźć odpowiednie predyktory, które mogą być pomocne w przewidywaniu interesującej nas cechy. Ma to szczególne znaczenie w problemach takich jak rozpoznawanie obrazów, w których nie jest łatwo wskazać, jak takie predyktory mogłyby wyglądać.
Sieć można łatwo rozbudować do olbrzymich rozmiarów, otrzymując bardzo skomplikowany model, który z regresją nie ma już praktycznie nic wspólnego. Co jednak ważne, aby to zrobić, zwykle potrzeba wielu obserwacji --- być może zbyt wielu, byśmy mogli jej użyć w naszym problemie.
Jaki model sprawdzi się w mojej sytuacji?
Po pierwsze, musimy si�ę zastanowić, czy problem, który chcemy rozwiązać, jest regresyjny czy klasyfikacyjny. W tym pierwszym możemy użyć wszystkich podanych algorytmów poza regresją logistyczną, w tym drugim wszystkich prócz regresji liniowej. Dalej, powinniśmy ustalić, na czym nam bardziej zależy: na zrozumieniu zjawiska czy prognozie nowych przypadków? Jeśli to pierwsze jest ważniejsze, potrzebujemy modelu, z którego będziemy w stanie wyciągnąć jak najwięcej wiarygodnych wniosków. Dobrym wyborem może być regresja lub drzewo decyzyjne. Jeśli natomiast skupiamy się na prognozie, jest duża szansa, że las losowy lub Extreme Gradient Boosting okażą się lepsze.
Czy w takim razie możemy z góry powiedzieć, że konkretny algorytm będzie najlepszy? Nie. Standardem w budowie modelu jest testowanie różnych podejść, od bardzo prostych do bardzo złożonych (o ile na te ostatnie mamy wystarczająco dużo obserwacji). Nawet jeśli interesuje nas prognoza, natura zjawiska może być taka, że akurat regresja okaże się najlepsza. Z drugiej strony, mimo że chcielibyśmy zrozumieć jakąś relację, to może być tak skomplikowane (lub nie mamy dostępu do odpowiednich predyktorów), że regresja jedynie wprowadzi nas w błąd. Cała rzecz w tym, że zanim nie zaczniemy budowy modelu, często nie wiemy, jakiej relacji się spodziewać.
Jeżeli chcesz wiedzieć więcej na temat uczenia maszynowego, koniecznie przeczytaj poprzednie artykuły:
- Uczenie maszynowe dla menedżerów
- Czym jest model uczenia maszynowego? - przewodnik dla menedżerów
- Jak znaleźć najlepszy model uczenia maszynowego?
Sprawdź również nasze szkolenia z kategorii Data Science.



