



Artykuł "Czym jest model uczenia maszynowego?" zakończyłem stwierdzeniem, że testowanie różnych algorytmów uczenia maszynowego polega na tym, że po prostu je stosujemy i patrzymy, jak działają. Może się to wydawać banalne, ale wcale tak nie jest i zatrzymamy się dłużej nad tym zdaniem. Co więcej, to podejście w pewien sposób odróżnia uczenie maszynowe od wykorzystywanych klasycznie metod statystycznych. Mój poprzedni artykuł znajdziesz tutaj.
Podejście klasyczne a uczenie maszynowe
Zaczniemy od przyjrzenia się, w jaki sposób statystyka jest najczęściej wykorzystywana w nauce. W większości przypadków przy jej pomocy chcemy zweryfikować pewne postawione wcześniej hipotezy (wnioskowanie statystyczne). W tym celu korzystamy z modeli i tak zwanych testów statystycznych. Zwykle są one osadzone w pewnych założeniach i aby móc wyciągnąć uprawnione wnioski, należy się wcześniej upewnić, czy te założenia są spełnione. To podejście nazywam ,,klasycznym''. Gdy próbujemy przewidzieć wartości cechy (Y), możemy skorzystać z tych samych modeli, ale kluczowy będzie nie tyle statystyczny rygor (założenia), ale to, czy model działa -- bo w problemach biznesowych zwykle to nas interesuje.
Jak sprawdzić, czy model działa?
Jeśli chcemy przewidzieć cechę (Y) na podstawie predyktorów (X), potrzebujemy historycznych wartości zarówno (X), jak i (Y). Budujemy model, który następnie możemy użyć na nowych wartościach (X), otrzymując szacunkową wartość (Y). Czy będzie ona bliska prawdy? Tego nie wiemy, bo oczywiście jej nie znamy. Ale możemy zastosować model na tych samych historycznych danych, które zostały wykorzystane do jego budowy. Otrzymamy wtedy wiele szacunkowych wartości (Y), które możemy porównać z prawdziwymi. Jeśli przewidywana cecha jest jakościowa (na przykład spłata kredytu), możemy policzyć, w ilu procentach przypadków się pomyliliśmy. Jeśli z kolei prognozujemy cechę ilościową (na przykład liczbę sprzedanych książek), możemy uśrednić różnice między szacunkowymi a prawdziwymi wartościami.
Wyżej wymienione miary, mimo że całkiem intuicyjne, w praktyce niekoniecznie muszą być najlepsze do podsumowania modelu i w wielu rzeczywistych problemach wykorzystuje się inne. Nie zmienia to jednak faktu, że mamy sposób, by określić, jak dobry jest dany model: należy zmierzyć, jak bardzo rzeczywiste wartości (Y) różnią się od przewidywanych (i często można to określić przy pomocy jednej liczby). Co więcej, gdy zaproponujemy kilka konkurencyjnych modeli, przy pomocy tego typu miar możemy wybrać najlepszy.
Nadmierne dopasowanie
Czy w takim razie nie musimy się przejmować, jak wygląda model, jak bardzo jest skomplikowany albo jak do niego doszliśmy, byleby tylko wybrana miara wskazywała na to, że przewidywane wartości są bliskie rzeczywistym? Tak i nie.
Teoretycznie, skoro interesuje nas tylko wynik, nie musimy wnikać, w jaki sposób do niego doszliśmy. Proponuję zatem następujący model: przewidujmy (Y) przy pomocy jego samego. Błąd takiego modelu jest zerowy, ale w żadnym razie nie nadaje się do zastosowania w praktyce, na nowych danych. Przykład jest oczywiście absurdalny i wydaje się, że nikomu nie przyszłoby do głowy, by w ten sposób podejść do sprawy. Okazuje się jednak, że wiele modeli uczenia maszynowego można tak bardzo skomplikować (uzależnić od bardzo dużej liczby parametrów), że będą one idealnie dopasowywać się do danych historycznych i w praktyce działać jak ten absurdalny model zaproponowany wyżej. Mówimy wtedy o tak zwanym nadmiernym dopasowaniu (choć popularniejszy jest angielski termin overfitting). Ryzyko tego zjawiska jest na tyle duże, że należy przedsięwziąć specjalne środki ostrożności: testować działanie modelu na innych danych, niż te, które zostały użyte do jego budowy.
Zbiór treningowy i testowy
Powyższe zalecenie realizuje się zwykle w następujący sposób. Dane dzielimy na dwa zbiory: tak zwany treningowy i testowy. Stosuje się różne proporcje, na przykład 80% i 20%. Udajemy, że nie mamy dostępu do zbioru testowego i model budujemy tylko na danych treningowych. Następnie na danych testowych sprawdzamy, jak działa, korzystając z miar, o których była mowa wyżej. Tym sposobem nie powinniśmy nadmiernie dopasować się do danych testowych (bo ich nie używamy) i obliczone wartości miar będą wiarygodne. Odpowiada do sytuacji, która najbardziej nas interesuje: czy model będzie działał na zupełnie nowych danych. Ostatecznie, gdy wybierzemy najlepszą metodę konstrukcji modelu, użyjemy wszystkich danych do jego budowy.
Odpowiadając jeszcze raz na pytanie, czy nie musimy się przejmować, w jaki sposób model został skonstruowany: nie, nie musimy, o ile na zbiorze testowym działa dobrze. Co prawda w rzeczywistości może wystąpić jeszcze wiele problemów, ale omówimy je w dalszych częściach.
Hiperparametry
Zbiór testowy wykorzystujemy do oceny, jak dobry jest nasz model, do porównywania kilku-kilkunastu konkurencyjnych modeli. Jednak w poprzednim artykule, gdy omówiłem algorytm najbliższych sąsiadów, napotkaliśmy na problem wyboru ich liczby. Być może czytelnikowi przychodzi właśnie do głowy, jak można by temu zaradzić: sprawdźmy na zbiorze testowym, jak działa model dla różnej liczby sąsiadów, na przykład 5, 10, 30. Ta intuicja jest bardzo dobra. Co prawda, jak zaraz wyjaśnimy, jest pewien problem z tym podejściem, ale sam pomysł świadczy o tym, że przyswoiliśmy najważniejszą ideę uczenia maszynowego.
Ale czemu sprawdzenie na zbiorze testowym, jaką liczbę sąsiadów przyjąć, niekoniecznie jest najlepszym pomysłem? Zacznijmy od tego, że sytuacja, w której ustalenie pewnych wartości jest niezbędne, aby dopasować model, jest typowa w uczeniu maszynowym. Takie wartości nazywamy hiperparametrami, w odróżnieniu od parametrów, które są ustalane w wyniku zastosowania metody (w przypadku metody najbliższych sąsiadów są to odległości do poszczególnych obserwacji). Niektóre metody mają tych hiperparametrów więcej, przez co ich ustalenie na zbiorze testowym wymagałoby sprawdzenia wielu kombinacji. Innymi słowy, musielibyśmy zadać mnóstwo pytań temu zbiorowi, czego skutkiem mogłoby być nadmierne dopasowanie do niego. Czyli zbiór testowy przestałby spełniać swoją funkcję.
Rozwiązaniem jest wydzielenie jeszcze jednego zbioru, tak zwanego walidacyjnego. Można to zrobić na przykład w proporcjach 60%/20%/20% (zbiór treningowy, walidacyjny, testowy). Na tym zbiorze testujemy różne wartości hiperparametrów i wybieramy najlepsze. Postępujemy w ten sposób dla różnych algorytmów uczenia maszynowego (gdyż prawie wszystkiego wymagają wyboru hiperparametrów). Na zbiorze testowym sprawdzamy, jak działają, ale z już optymalnymi hiperparametrami.
Ten schemat również ma pewne wady i istnieją popularne modyfikacje, na przykład tak zwana kroswalidacja. Z kolei niektóre z hiperparametrów można wyznaczyć na podstawie różnych heurystyk czy intuicji.

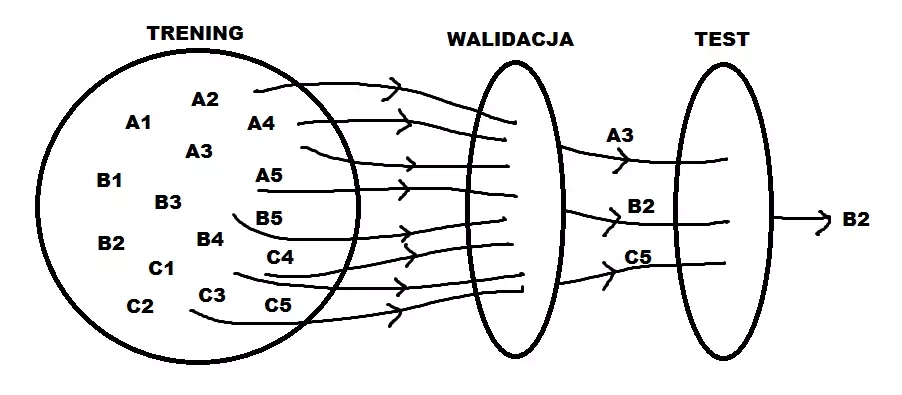
Na powyższym rysunku rozpatrujemy modele A, B i C, każdy z pięcioma hiperparametrami. Budujemy je na zbiorze treningowym, wybieramy optymalne hiperparametry na walidacyjnym, decydujemy się na najlepszy model na testowym.
Podsumowanie
Czego do tej pory się nauczyliśmy? W pierwszym artykule przedstawiłem całościowo proces budowy modelu, wyróżniłem kilka etapów. W tym i poprzednim artykule zająłem się sercem budowy modelu, czyli matematycznym opisem relacji między (Y) a (X). Stwierdziłem, że ten etap zwykle nie zajmuje najwięcej czasu, mimo to poświęcam mu tyle miejsca, gdyż wydaje się najbardziej magiczny. Samo pojęcie modelu może być odbierane magicznie, ale jak już wiemy, jest to po prostu matematyczna funkcja, która dla pewnych konkretnych wartości (X_1, X_2, \ldots, X_p) zwraca wartość (Y). Do postaci tej funkcji nie dochodzimy na podstawie teorii czy intuicji, ale w oparciu o historyczne dane (mając przy tym nadzieję, że badana relacja będzie taka sama w przeszłości).
Aby wybrać najlepszy model, nie wykorzystujemy wszystkich danych, gdyż potrzebujemy części, by móc ocenić, jak ten model działa (niektórzy trochę prześmiewczo twierdzą, że uczenie maszynowego różni się od statystyki tym, że dzielimy dane na treningowe i testowe). Do oceny działania modelu wykorzystujemy odpowiednie miary, zwykle określające, jak daleko przewidywana wartość (Y) jest od rzeczywistej. Co więcej, taką miarę używamy nie tylko do oceny, jak model działa, ale też do ustalenia hiperparametrów i do wybrania jednego modelu z wielu konkurencyjnych. To ostatnie stwierdzenie można uznać za główną ideę uczenia maszynowego: skoro chcemy, by model rzadko się mylił, wybierzmy po prostu taki, który to robi najrzadziej. Czyli w konstrukcję modelu jest wbudowany cel biznesowy.
W kolejnym artykule poznamy inne metody poza najbliższymi sąsiadami, najbardziej obecnie popularne w świecie uczenia maszynowego, dzięki czemu powinniśmy jeszcze lepiej zrozumieć, czym tak naprawdę jest model.
Jesteś menedżerem? Chcesz nabyć kompetencje w wykorzystywaniu zagadnień związanych z Big Data i Data Science? Dodatkowo zdobyć wiedzę w zakresie specyfiki dużych danych, integracji i gromadzenia danych z różnych źródeł oraz architektury rozwiązań klasy Big Data? Jeżeli tak, to koniecznie sprawdź program naszych studiów podyplomowych Data Science i Big Data w zarządzaniu.



