




Hibernate jest bardzo popularnym frameworkiem typu ORM (Object-relational mapping) dedykowanym dla programów pisanych w Javie czy też innych językach uruchamianych w maszynie wirtualnej Javy, np. w Kotlinie. Tego typu narzędzia umożliwiają dwukierunkowe odwzorowywanie świata relacji baz danych na świat obiektów. Popularność relacyjnych baz danych jako składowisk znajduje swoje odbicie w popularności rozwiązań ORM. I - jak to często bywa - w tym miejscu pojawiają się często popełniane niedopatrzenia, skutkujące czy to niepoprawnym zachowaniem, czy też obniżeniem wydajności. Jednym z takich znanych problemów jest tytułowy problem n + 1, o którym traktuje ten wpis.
Problem n + 1
Problem n + 1 może pojawić się w przypadku, w którym jedna z encji (tabel) odwołuje się do innej encji (tabeli). W takiej sytuacji zdarza się, że w celu pobrania wartości encji zależnej wykonywanych jest n nadmiarowych zapytań podczas, gdy wystarczyłoby tylko jedno. Nie trzeba nikogo przekonywać, że ma to negatywny wpływ na wydajność systemu i generuje niepotrzebne obciążenie bazy danych. Zwłaszcza że liczba zapytań rośnie wraz z n.
Sam problem jest często przedstawiany jako występujący tylko w relacji jeden do wielu (javax.persistence.OneToMany) bądź jedynie w przypadku leniwego ładowania danych (javax.persistence.FetchType.LAZY). Jest to nieprawda i należy pamiętać, że problem ten może wystąpić również w relacji jeden do jeden oraz przy “zachłannym” ładowaniu encji zależnych.
Wyobraźmy sobie, że modelujemy relację pudełka i zabawek. Na początku stwórzmy prostą klasę, która umożliwia pobranie określonej liczby pudełek z bazy danych:
1class Storage { 2 fun getBoxes(limit: Int): List<Box> { 3 return getEntityManager() 4 .createQuery("select b from Box b order by id", 5 Box::class.java) 6 .setMaxResults(limit) 7 .resultList 8 } 9 10 private fun getEntityManager(): EntityManager { 11 return Persistence.createEntityManagerFactory("persistence") 12 .createEntityManager() 13 } 14} 15 16fun main(args: Array<String>) { 17 val storage = Storage() 18 println(storage.getBoxes(4)) 19}
A teraz zamodelujmy relację pudełko-zabawki. Załóżmy, że wiele zabawek może należeć do jednego pudełka. Schemat bazy danych mógłby wyglądać tak:

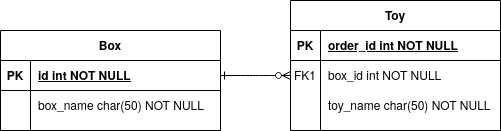
Widzimy tutaj relację jeden do wielu pomiędzy tabelami. Korzystając z JPA (Java Persistence API) w implementacji Hibernate możemy zapisać to w języku Kotlin w sposób następujący:
1@Table(name = "box") 2@Entity 3data class Box( 4 @Id 5 @GeneratedValue(strategy = GenerationType.AUTO) 6 val id: Int, 7 8 @Column(name = "name", length = 50, nullable = false) 9 val name: String, 10 11 @OneToMany(fetch = FetchType.EAGER, cascade = [CascadeType.ALL]) 12 @JoinColumn(name = "box_id") 13 val toys: List<Toy> 14) 15 16@Table(name = "toy") 17@Entity 18data class Toy( 19 @Id 20 @GeneratedValue(strategy = GenerationType.AUTO) 21 val id: Int, 22 23 @Column(name = "name", length = 50, nullable = false) 24 val name: String 25)
Wykonajmy zapytanie z funkcji main, które ma za zadanie pobrać cztery pudełka z bazy danych i popatrzmy na wykonane zapytania przez Hibernate:
1select box.id, box.name from box order by box.id limit 4 2select toy.box_id, toy.id, toy.name from toy where toy.box_id=4 3select toy.box_id, toy.id, toy.name from toy where toy.box_id=2 4select toy.box_id, toy.id, toy.name from toy where toy.box_id=1 5select toy.box_id, toy.id, toy.name from toy where toy.box_id=3
Wyraźnie widać, że zostało wykonane 4 + 1 zapytań w celu pobrania czterech pudełek. Najpierw Hibernate pobrał cztery dowolne pudełka, po czym dla każdego z nich wykonał po jednym zapytaniu, żeby pobrać zabawki doń należące. Zadanie to mogłoby zostać z powodzeniem wykonane, używając tylko jednego zapytania, zmieniając samo zapytanie JPQL:
1fun getBoxes(limit: Int): List<Box> { 2 return getEntityManager() 3 .createQuery("select b from Box b join fetch b.toys order by 4 b.id", Box::class.java) 5 .setMaxResults(limit) 6 .resultList 7}
Teraz, liczba wysłanych zapytań do bazy danych została zredukowana do jednego:
1select box.id, toy.id, box.name, toy.name, toy.box_id, from box inner join toy on box.id=toy.box_id order by box.id
Nie zawsze jednak najlepszym sposobem na wykonanie tego typu zadania jest pisanie własnych zapytań. Co w sytuacji, gdy korzystamy np. z repozytoriów dostarczanych przez Spring Data? Istnieje jeszcze inne podejście do rozwiązania tego problemu, a mianowicie posłużenie się adnotacją org.hibernate.annotations.BatchSize, którą możemy odnaleźć w bibliotece Hibernate ORM Hibernate Core. Zastosujemy tę adnotację umieszczając ją nad polem toys:
1@Table(name = "box") 2@Entity 3data class Box( 4 @Id 5 @GeneratedValue(strategy = GenerationType.AUTO) 6 val id: Int, 7 8 @Column(name = "name", length = 50, nullable = false) 9 val name: String, 10 11 @OneToMany(fetch = FetchType.EAGER, cascade = [CascadeType.ALL]) 12 @JoinColumn(name = "box_id") 13 @BatchSize(size = 256) 14 val toys: List<Toy> 15)
Dodanie adnotacji @BatchSize nad polem toys sprawia, że Hibernate będzie pobierał dane o zabawkach przypisanych danym pudełkom “paczkami” (batchowo), tj. dla do 256 instancji Box, Hibernate pobierze ich zabawki w ramach jednego zapytania. Spójrzmy na zapytania, które zostały wygenerowane dla pierwszej wersji funkcji getBoxes:
1select box.id, box.name from box order by box.id limit 4 2select toy.box_id, toy.id, toy.name from toy where toy.box_id in 3 (4, 1, 2, 3)
Bezsprzecznie widać, że drugie zapytanie pobiera całą “paczkę” pudełek. Jeżeli natomiast rozmiar paczki zostałby ograniczony do dwóch (@BatchSize(size = 2)) to ujrzelibyśmy dwa zapytania, każde pobierające po dwa elementy na paczkę:
1select box.id, box.name from box order by box.id limit 4 2select toy.box_id, toy.id, toy.name from toy where toy.box_id in 3 (4, 1) 4select toy.box_id, toy.id, toy.name from toy where toy.box_id in 5 (2, 3)
Podsumowanie
Relacje typu jeden do jeden czy też typu jeden do wielu są zupełnie naturalne w relacyjnych systemach baz danych. Z tego też powodu nierzadko można spotkać się z tym problemem w aplikacjach, które korzystają z Hibernate. Przedstawione tutaj wyniki zostały uzyskane, korzystając z bibliotek:
- Hibernate Core Relocation 5.4.24.Final,
- Hibernate JPA 2.0 API 1.0.0.Final,
- MySQL Connector/J 8.0.22, oraz z bazy danych MySQL 5.7.25. Zapytania dla czytelności zostały nieco uproszczone, ale ich znaczenie i sens zostały całkowicie zachowane.



